4. System upgrade: RLTFR8#
If the number of second members to be solved simultaneously is greater than 4, a block method implemented by routine RLBFR8 is used, otherwise MLTDRA is called for each second member.
Data: these are the pointers from MLTPRE:
\(\mathit{ADRESS}\),
\(\mathit{GLOBAL}\),
\(\mathit{SUPND}\),
\(\mathit{LGSN}\),
\(\mathit{ANC}\),
\(\mathit{NOUV}\),
\(\mathit{SEQ}\),
\(\mathit{LGBLOC}\),
\(\mathit{NCBLOC}\),
\(\mathit{DECAL}\).
And the factored matrix from MULFR8
\(\mathit{FACTOL}\):. VALF (and \(\mathit{FACTOU}\):. WALF in non-symmetric)
The second members:
\(\mathit{XSOL}(\mathrm{1 }\mathrm{:}\mathrm{\ne },\mathrm{1 }\mathrm{:}\mathit{NBSOL})\)
Results: They are found in the table that contained the second members: \(\mathit{XSOL}\).
4.1. MLTDRA#
This routine performs, for a single second member, the descent, the division by the term diagonal, and the ascent successively. In the descent, we use the matrix-vector product \(\mathit{DGEMV}\) from Blas libraries, beyond a certain threshold. Below we optimize « by hand » in routine SSPMVB.
(This optimization is a vectorization written for CRAY, so it could be reviewed or even removed! )
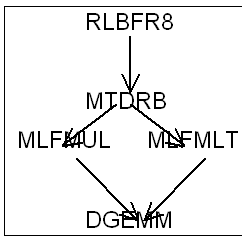
4.2. RLBFR8#
In the presence of several second members, the calls to DGEMV mentioned in the preceding paragraph are replaced by calls to DGEMM, matrix*matrix product, on matrix blocks of order \(\mathit{NB}\). We thus aim at the performance provided by these level 3 Blas, as in numerical factorization.
The routines called are:
|
Figure 5 Descent-ascent by blocks