1. Problem#
In numerical simulation of physical phenomena, a significant computational cost often comes from the construction and resolution of linear systems. Structural mechanics is no exception to the rule! The cost of building the system depends on the number of integration points and on the complexity of the laws of behavior, while that of solving is linked to the number of unknowns, to the models used and to the topology (width of the band, conditioning). When the number of unknowns explodes, the second step becomes preponderant [1] _ and it is therefore the latter that will mainly interest us here. Moreover, when it is possible to be more efficient in this resolution phase, thanks to access to a parallel machine, this advantage can be propagated to the phase of constitution of the system itself (elementary calculations and assemblies, cf. [U2.08.06]).
These inversions of linear systems are in fact omnipresent in codes and often buried in the depths of other numerical algorithms: non-linear schema, time integration, modal analysis… For example, we are looking for the vector of nodal displacements (or displacement increments) \(u\) verifying a linear system of the type
\(\mathrm{Ku}=f\) (1-1)
with \(K\) a stiffness matrix and \(f\) a vector representing the application of generalized forces to the mechanical system.
In general, the resolution of this type of problem requires a (more) broad question than it seems:
Do we have access to the matrix or do we simply know its action on a vector?
Is this matrix hollow or dense?
What are its numerical properties (symmetry, positive definite…) and structural properties (real/complex, by bands, by blocks…)?
Do we want to solve a single system (1-1), several simultaneously [2] _
or consecutively [3] _ ? Even several different and successive systems whose matrices are very similar [4] _ ?
In the case of successive resolutions, can we reuse previous results in order to facilitate future resolutions (cf. restart technique, partial factorization)?
What is the order of magnitude of the size of the problem, of the matrix and of its factorized in relation to the processing capacities of CPU and associated memories (RAM, disk)?
Do we want a very precise solution or simply an estimate (cf. nested solvers)?
Do we have access to linear algebra libraries (and their prerequisites MPI, BLAS, LAPACK…) or should we use « homemade » products?
In Code_Aster, we explicitly build the matrix and store it in the format MORSE [5] _ . With most models, the matrix is sparse (due to discretization by finite elements), potentially poorly conditioned [6] _
and often real, symmetric, and indefinite [7] _ . In non-linear, modal or thermo-mechanical combinations, problems such as « multiple second members » are often treated. Discrete contact and friction methods take advantage of partial factorization capabilities. On the other hand, Code_Aster also uses simultaneous resolution scenarios (Schur complements of contact and substructuring…).
As for the sizes of the problems, even if they increase from year to year, they remain modest compared to CFD: in the order of a million unknowns but for hundreds of steps of time or Newton iterations.
Moreover, from a « middleware and hardware » point of view, the code is now based on numerous optimized and sustainable libraries (MPI, BLAS, LAPACK, METIS, SCOTCH, PETSc, MUMPS…) and is mainly used on SMP clusters ** (fast networks, large storage capacity…) and is mainly used on clusters (fast networks, large storage capacity…) RAM and disc). The main aim is therefore to optimize the use of linear solvers in this perspective.
For 60 years, two types of techniques have been competing for supremacy in the field, direct solvers and iterative solvers (cf. [Che05] [Dav06] [Duf06] [Gol96] [LT98] [] [] [] [] [Liu89] [Liu89] [Meu99] [Saa03]).
The first ones are robust and result in a finite number of operations (theoretically) known in advance. Their theory is relatively well completed and their declination according to many types of matrices and software architectures is very complete. In particular, their multi-level algorithm is well adapted to the memory hierarchies of current machines. However, they require storage capacities that grow rapidly with the size of the problem, which limits the scalability of their parallelism. [8] _ . Even if this parallelism can be broken down into several independent layers, thus increasing performance.
On the other hand, iterative methods are more « scalable » when the number of processors is increased. Their theory is full of numerous « open problems », especially in finite arithmetic. In practice, their convergence into a « reasonable » number of iterations is not always acquired, it depends on the structure of the matrix, the starting point, the stopping criterion… This type of solvers has more difficulty in breaking through industrial structures in mechanics where we often combine heterogeneities, non-linearities and model junctions that complicate the conditioning of the work operator. On the other hand, they are not adapted to effectively solve « multiple second member » problems. Except these are very common in the algorithmic of mechanical simulations.
Unlike their direct counterparts, it is not possible to offer THE iterative solver that will solve any linear system. The suitability of the type of algorithm to a class of problems is done on a case-by-case basis. However, they have other advantages that have historically given them the right of choice for certain applications. With equivalent memory management, they require less than direct solvers, because you just need to know the action of the matrix on any vector, without really having to store it. On the other hand, we are not subject to the « dictate » of the filling phenomenon, which deteriorates the profile of the matrices, we can effectively exploit the hollow nature of the operators and control the precision of the results [9] _ .
In the numerical analysis literature, a predominant place is often given to iterative solvers in general, and to conjugate gradient variants in particular. The most experienced authors agree that, even if its use is gaining over the years and variants, « market shares », some areas are still resistant. These include structural mechanics, electronic circuit simulation…
To paraphrase these authors, the use of direct solvers is in the field of technology, while choosing the right iterative method/preconditioner couple is rather an art! Despite its biblical simplicity on paper, resolving a linear system, even a symmetric definite positive one, is not « a long quiet river. » Between two evils, filling/pivoting and preconditioning, you have to choose!
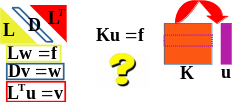
Figure 1-1._ Two classes of methods to solve
a linear system: the direct and the iterative.
Recently, the arrival of hybrid solvers [Boi08], which mix the two approaches to take advantage of their respective advantages, is changing the situation a bit. On « border simulations » comprising tens of millions of unknowns, the conjugate gradient may even compete with these new approaches (especially for multiple second-member problems).
- But in fact it is generally present as an interface solver for these hybrids. These can be seen as particular preconditioners (multilevel, multigrid, DD) of a conjugate gradient or any other Krylov method (GMRES, BICG-Stab…). On the other hand, given its simplicity of implementation (sequentially as well as in parallel) and its low memory occupancy, it is often the only alternative to tackle very big problems [10] _
.
Notes:
The two main families of solvers should be seen as complementary rather than competing. We often try to mix them: DD methods [Boi08], preconditioner by incomplete factorization (cf.*§ 4.2) or multigrid [Tar09], iterative refinement procedure at the end of the direct solver [Boi09]…
For more details on the linear algebra libraries implementing these methods and some benchmark results comparing them, you can consult the documentation [Boi09]. But to really take advantage of these products, you have to exploit them in parallel mode. The [Boi08] documentation illustrates some aspects of parallel computing (hardware, methodology, methodology, languages, performance indicators) and specifies the different levels of parallelism that can be used in code such as Code_Aster.
Let us now discuss all the chapters around which this note will be based. After explaining the different formulations of the problem (linear system, functional minimizations) and in order to better make the reader feel the implicit subtleties of gradient-type methods, we propose a quick overview of their fundamentals: the classical « steepest-descent » then the general descent methods as well as their links with the GC. With these reminders in place, the algorithmic workflow of GC becomes clear (at least we hope so!) and its theoretical properties of convergence, orthogonality and complexity derive from this. Complements are quickly drawn up to put the GC into perspective with recurring notions in numerical analysis: Petrov-Galerkin projection and Krylov space, orthogonalization problem, equivalence with the Lanczos method and spectral properties, nested solvers and parallelism.
Then we detail the « necessary evil » that is preconditioning the work operator, some strategies that are often used and those retained for the native GCPC of Code_Aster and for the solvers of PETSc.
We conclude with the particular implementation difficulties in the code, the parameter and perimeter questions as well as some usage advice.
Note:
The effective implementation and maintenance of iterative solvers in Code_Aster is the result of teamwork: J.P.Grégoire, J.Pellet, T.deSoza, N.Tardieu, O.Boiteau…
In this document, many of the figures were taken from J.R. Shewchuk’s introduction paper [Sh94] with his kind permission: ©1994 by Jonathan Richard Shewchuk.